Ob Nachrichten, Produktrezensionen oder Forenkommentare – häufig gibt es Situationen, in denen kurze Texte in großer Anzahl zu einem Thema veröffentlicht werden. Wir prüfen in diesem Blogbeitrag einfache Strategien, die Grundstimmung solcher Texte maschinell beurteilen zu lassen.
Im Beitrag Das Wichtigste in Kürze hatten wir uns bereits einmal mit Text Mining beschäftigt. Stand dort die Herausforderung im Mittelpunkt, die Besonderheiten eines Textes im Vergleich zu einer Menge von anderen Texten herauszuarbeiten – etwa in Form einer charakteristischen Wortwolke -, so beschäftigen wir uns diesmal mit der Analyse der Stimmung eines Textes, also mit der sogenannten Sentiment Analysis.
Sentiment-Analyse findet immer dann Anwendung, wenn eine größere Anzahl von normalerweise eher kurzen Texten automatisiert auf ihre Grundstimmung, die Polarität untersucht werden soll. Die zu beantwortende Frage lautet dann: „Hat der Beitrag eine positive oder eine negative Tendenz?“
Oft – wie etwa bei einer Rezension – wird eine zusammenfassende Wertung gleich mitgeliefert. Nichtdestotrotz kann auch eine sehr gute Bewertung abwertende Sätze mit negativer Stimmung enthalten, und es hilft, solche Bemerkungen identifizieren und sammeln zu können. Weiterhin gäbe es noch die aspektorientierte Analyse, die versucht, die Bewertung einzelner Eigenschaften etwa eines Produktes automatisiert zu erkennen.

Beispiele für Sätze mit noch undefinierter Polarität
Wir verwenden in diesem Beitrag die Granularität auf der Satzebene. Für einen übergeordneten Text können dann unterschiedliche aggregierende Maße berechnet werden, die sich aus den einzelnen Satzbewertungen ergeben, wie beispielsweise der Durchschnitt oder der größte positive Wert.
Schauen wir doch einmal auf ein paar Beispielsätze, die bei Amazon in längeren Rezensionen zu einem Ventilator (zum Modell, welches gerade vor mir steht und selbst auf Stufe 1 recht laut ist) standen (5-8), bzw. hätten stehen können (1-4).
Bevor wir versuchen, die noch leere Spalte der Polarität zu füllen, ist eine Anmerkung zur Aufbereitung eines Textes (in Form der Tokenisierung) angebracht: Es ist bereits eine anspruchsvolle Aufgabe, einen gegebenen Text in Sätze und Wörter zu zerlegen. Abkürzungen, Umlaute und Rechtschreib- und Flüchtigkeitsfehler (wie hier „von einander“ und – kritischer! – „rekalamiert“) erschweren diesen Task ungemein, eingestreute Emojis kommen noch hinzu!
Wie nehmen der Einfachheit halber an, dass dieser Task in einer vorgelagerten Stufe erfolgreich durchgeführt wurde.
Mögliche Verfahren gibt es viele, auch die omnipräsenten Deep-Learning-Verfahren sind in der letzten Zeit verstärkt anzutreffen. Eine Recherche bei „scholar.google.de“ mit der Kombination „deep learning“ und „sentiment analysis“ führt zu 3300 Veröffentlichungen – allein im Jahre 2019!
Wir erheben hier somit nicht den Anspruch, das brandaktuelle State-of-the-Art-Verfahren mit der besten Performanz vorzustellen, sondern einen relativ leicht implementierbaren Ansatz mit dem Vorteil der Nachvollziehbarkeit der erzeugten Bewertungen. Ob auch die Qualität überzeugen kann, werden wir sehen…
Es handelt sich hierbei um ein Lexikon-basiertes Verfahren. Die Grundidee besteht darin, jeweils eine Negativ- und eine Positivliste von Wörtern zu führen und jedes Wort auf einer Skala von -1 bis +1 zu bewerten. Wörter ohne Erwähnung werden neutral mit 0 notiert. Die Bewertung eines ganzen Satzes besteht einfach aus der Summe der positiven und negativen Wortbewertungen. In dieser einfachsten Variante des Algorithmus – ein Satz wird als „bag of words“ gesehen – könnte man die Wörter bunt durcheinanderwürfeln und käme trotzdem zur gleichen Bewertung.
Normalerweise wird diese Summe noch durch einen Ausdruck dividiert, der monoton mit der Gesamtanzahl der Wörter eines Satzes wächst – wenn also die Anzahl der neutralen Wörter steigt, bewegt sich der Gesamtscore eines Satzes in Richtung null.
Dieser Ansatz „versteht“ einen Satz nicht: Ein Satz wird somit nicht nach grammatikalischen Regeln seziert – allein aus dem Auftreten bestimmter Wörter wird eine bewertete Polarität berechnet. Damit kann man auch einmal danebenliegen, aber Änderungen der Stimmungen einer großen Anzahl etwa von Twitterbeiträgen oder Kundenanfragen können durchaus erfasst werden.
Im Web finden sich bereits fertig kompilierte Listen mit negativ und positiv besetzten Wörtern inklusive Bewertungen, die meisten davon aber in englischer Sprache.
Eine kurze Evaluierung einer umfangreichen deutschen Liste hat nun ergeben, dass etwa das Wort „laut“, welches bei einem Ventilator größere Bedeutung besitzt, in dieser Liste leider gar nicht auftaucht, ebenso wenig wie „Geräusch“. „Lautstark“ war hingegen vorhanden, war dabei jedoch mit 0.04 sogar als leicht positiv eingeschätzt!
Für allgemeine Texte mag dieser Wortschatz genügen und passen, für speziellere Anwendungen muss der gegebene Kontext, in welchem der Algorithmus verwendet werden soll, immer berücksichtigt werden. Für unseren Fall bedarf es einer maßgeschneiderten Liste mit eigenen Bewertungen.
Die Bewertungen einzelner Wörter können nun beispielsweise über einen Machine-Learning-Ansatz mit positiv und negativ gelabelten Beispielsätzen generiert werden, die aber dann auch in größerer Zahl und Variation vorliegen müssen.
Alternativ kann eine handverlesene, kuratierte Liste erstellt werden. Dazu haben wir zunächst Häufigkeiten bei den in den Rezensionen verwendeten Begriffen maschinell gezählt und ausgewertet. Die auftauchenden Adjektive und Substantive mit einer ausgeprägten Polarität sind weniger vielfältig als vorher vermutet. Mit nur jeweils 10 positiven, bzw. negativen Wörtern (zuzüglich der davon abgeleiteten Begriffe) werden schon die meisten Ventilator-Produktbewertungen gut erfasst.
Die Bewertungen wurden hier manuell vergeben, sortiert nach der empfundenen Stärke der Aussage (dieser Part könnte – wie bereits erwähnt! – nach der abgeschlossenen Fleißarbeit des Sammelns und Labelns deutlich größerer Anzahlen von Rezensionen auch automatisiert werden!).
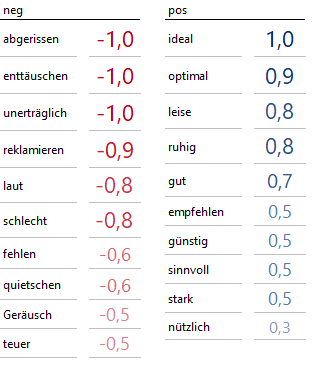
Kurze Listen für das Beispiel Ventilator
Hier wird nicht nur die Grundform eines Substantivs oder eines Adjektivs berücksichtigt, sondern auch eine Reihe von Beugungen, die für jedes Wort zur Verfügung stehen. Bei „gut“ werden auch Wörter wie „gute“ oder „guter“ mit der gleichen Bewertung versehen.
Zur Auswertung haben wir das R-Paket sentimentr verwendet, erst einmal ohne die vom Autor propagierten „sentiment shifters“ (dazu gleich mehr):

Simpler Ansatz – noch mit Verbesserungspotenzial!
Für einen ersten Wurf sieht das schon gar nicht schlecht aus, es gibt aber offensichtliche Schwächen: „Der Ventilator ist nicht zu laut“ – hier wurde die Verneinung nicht berücksichtigt und fälschlicherweise eine negative Bewertung vergeben. „Der Ventilator ist zu laut“ und „Der Ventilator ist ziemlich laut“ bekommen die gleiche Bewertung, obwohl ersterer Fall einen schlechteren Eindruck macht. Beim Beispiel mit der Bewertung 0 gelangt das Verfahren an seine Grenzen: Hier müsste überlegt werden, ob das einzige in Frage kommende Wort „einfach“ eine positive Polarität bekommen sollte.
Bei sentimentr gibt es deshalb eine Erweiterung um vier Wörtergruppen, die die ursprüngliche Bewertung ändern können. Unsere selbsterstellte deutsche Liste lautet:

Die vier Gruppen, die die Bewertung beeinflussen!
Wörter aus der ersten Gruppe kehren die Bewertung um: „nicht leise“, „kein Geräusch“. Die Wörter aus der zweiten Gruppe verstärken eine Bewertung: „sehr leise“, „extrem laut“. In der dritten Gruppe befinden sich abschwächende Wörter: „ziemlich leise“.
Ob ein Wort aus diesen drei Gruppen auf ein anderes mit Polarität einen Einfluss haben soll, wird über Parameter des Wortabstandes gesteuert: Wenn etwa ein Wortabstand von 2 Wörtern erlaubt ist, würde „kein einziges Geräusch“ eine Negation bedeuten, aber „kein einziges hörbares Geräusch“ nicht mehr, da der Abstand hier 3 Wörter beträgt. In dieser Variante hat die Satzstellung also durchaus einen Einfluss.
Es ist nur eine heuristische Regel: Wenn sich ein Rezensent einer sehr blumigen und ausschweifenden Sprache bedient, kann dieser Algorithmus die Zusammengehörigkeit nicht mehr erkennen: Der Satz „Es ist einfach nicht wahr, wie von anderen Rezensenten hier behauptet, dass der Ventilator laut sei.“ würde als negativ beurteilt werden, da das Wortpaar „nicht“ und „laut“ nicht in Bezug gesetzt werden kann.
Abgesehen davon zeigt dieser Satz auch die Schwierigkeit auf, das Wort „einfach“ grundsätzlich positiv zu bewerten. Andererseits kann selbst das Wort „laut“ in einem anderen Kontext auch eine neutrale Bedeutung haben: „Laut einer Umfrage sind alle Käufer Stammkunden geworden.“
Die letzte Gruppe 4 enthält schließlich Wörter, die einen Satzteil einleiten, der die vorangegangene Aussage abschwächt: „Der Ventilator ist teuer, aber er ist ja auch sehr gut!“ In dieser Konstruktion ist der hohe Preis dann weniger relevant. Es gibt Parameter, die die Gewichtungen beeinflussen; mit der Einstellung „amplifier.weight=0.5“ etwa erhöhen verstärkende Begriffe aus der 2. Gruppe den absoluten Wert eines Wortes um 50 Prozent, abschwächende Begriffe aus der 3. Gruppe senken ihn hingegen um 50 Prozent.
Es ergeben sich dann die folgenden aktualisierten Bewertungen:
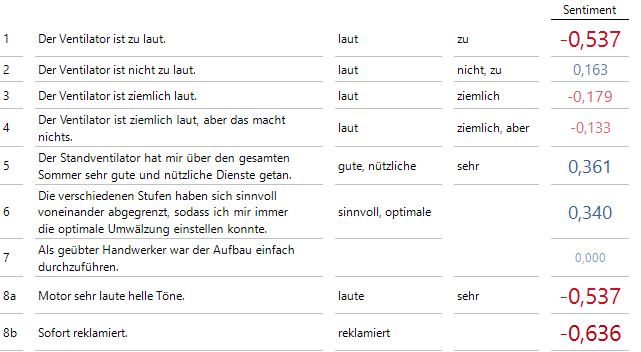
Die mit den Zusatzregeln neu berechneten Werte
In zwei Extraspalten sind hier einerseits die Wörter aufgeführt, die in einem Satz überhaupt bewertet werden, und andererseits die Wörter, die die Grundbewertung beeinflussen.
Das Ergebnis ist hier recht überzeugend. Man würde nun die erzeugten Satzbewertungen eine Zeit lang überprüfen, gegebenenfalls die Wörterliste ergänzen („vibrieren“, „nerven“,…) oder gleich Synonymsammlungen zu Rate ziehen.
Das Vokabular in diesem doch recht engen Kontext ist begrenzt und bereits nach kurzer Zeit sind die typischen Attribute bekannt.
Dann ist man in der Lage, etwa Sätze der besonderen Unzufriedenheit automatisiert zu erkennen. Natürlich können auch Wörterlisten verschiedener Produkte zusammengelegt werden – in einem Kontext nicht verwendete Wörter schaden ja nicht! Man muss also nicht bei jedem Produkt mit dem Aufbau einer Wörterliste von vorne anfangen.
Problematisch wird es nur, wenn Begriffe in unterschiedlichen Kontexten gegensätzlich oder zumindest unterschiedlich stark geladen sind, wie etwa das oben erwähnte „lautstark“, das bei Ventilatoren eine klar negative Stimmung ausdrückt.
Jede Rezension kann aus mehreren Sätzen bestehen. Es ist also durchaus sinnvoll, auf Rezensionsebene zusammenfassende Statistiken zu erstellen, um etwa auch in einer grundsätzlich positiven Rezension das Haar in der Suppe in Form eines negativ bewerteten Satzes erkennen zu können:
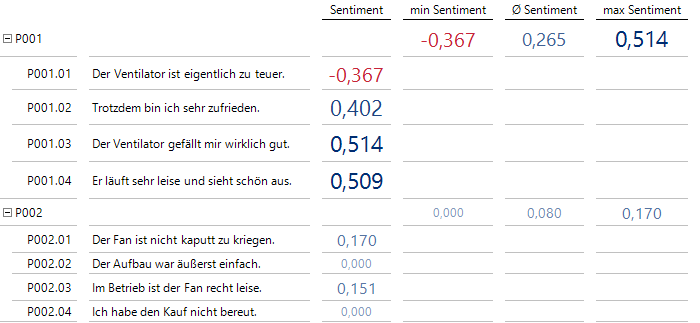
Statistiken auf Rezensionsebene
In einer bewerteten Tabelle lässt sich auch einfacher überblicken, ob bestimmte Wörter in die Bewertungsliste aufgenommen werden sollten; hier käme „bereuen“ als Kandidat in Frage, aber die negative Konnotation ergibt sich eigentlich nur zusammen mit „Kauf“.
Der vorgestellte Algorithmus hat also durchaus seine Daseinsberechtigung, aber man sollte keine automatisierte Literaturanalyse mit Zusammenfassung erwarten. Ironie ( „Nach 5 Minuten stellte das Gerät den Betrieb ein. Es ist jetzt sehr leise.“) oder zum Beispiel eigentlich positive Verweise auf die schlechtere Konkurrenz („Im Vergleich zu diesem Gerät sind meine beiden Ventilatoren von XYZ wesentlich lauter!“) werden mit diesem Ansatz falsch interpretiert. Auch wird manche Satzkonstellation nicht korrekt erfasst.
Eine gute Pflege der Wörterbasis vorausgesetzt, kann der Algorithmus aber prinzipiell durchaus nützlich sein. Je kürzer und direkter die Sätze, desto eher wird man als Mensch dem Ergebnis zustimmen.
Sätze, die beispielsweise Redewendungen beinhalten, deren Wirkung auf Polarität nur in ihrer Gesamtheit entstehen („Mit dem Kauf dieses Geräts bin ich vom Regen in die Traufe geraten“), werden mit dem genannten Ansatz jedoch nicht korrekt erfasst. Eine Abhilfe wäre durch die aufwändige Erstellung einer Liste von Redewendungen oder Floskeln gegeben, die als eine Einheit angesehen werden sollen – mit einer Bewertung pro Redewendung und nicht pro Wort.
Für einen Uploadfilter, der die schier unmögliche Aufgabe lösen soll, mit hundertprozentiger Sicherheit die Spreu vom Weizen zu trennen – und Plattformbetreiber und Anwender gleichermaßen zufriedenstellt, müssen wohl aber noch ganz andere Kaliber aufgeboten werden.
Quelle:
sentimentr
https://github.com/trinker/sentimentr

Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..